NLP Series - NLP Pipeline
Natural Language Processing Basics - NLP Pipeline
If there’s one form of media which we are exposed to every single day, it’s text. There is huge amounts of data created by people and devices, every single day. This data includes and is not limited to comments on social media, product reviews, tweets and reddit messages. Generally speaking, the data from these sources are useful for the purposes of research and commerce.
An NLP pipeline, refers to the series of steps involved in a text-processing pipeline used for any NLP application development. In this article, we will learn about the various steps involved and how they play important roles in solving the NLP problem. This article is part of Natural Language Processing series where we cover most prominent building blocks in building Natural Language Processing(NLP) applications. In this article, we shall discuss various stages involved in a data-driven NLP pipeline.
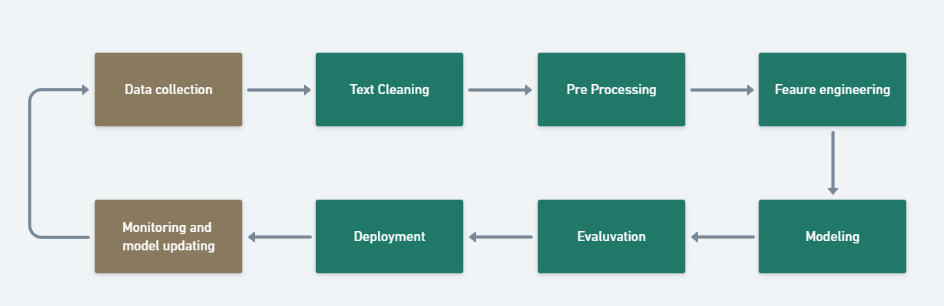
The key stages of an NLP pipeline for a data-driven NLP system are as follows.
1. Data acquisition
2. Text cleaning
3. Pre-processing
4. Feature engineering
5. Modeling
6. Evaluation
7. Deployment
8. Monitoring & Updating Model
Before we dive into the details of each stage of the NLP pipeline, its important to note that each of these steps may depend on the specific NLP task at hand. A text classification task may require different stages compared to a text summarization tasl.
Data Acquisition
Data is the heart of the machine learning world and therefore its vital to understand the source of data and the strategies useful for gathering data. There are several ways to collect data. Firstly, we could check if there are any publicly available datasets for the task at hand. These refer to the pre-cleaned, freely available datasets. When our problem statement aligns with a clean, pre-existing, properly formulated dataset, we should certainly take advantage of existing, open-source expertise.
Although there are a number of publicly available datasets for a wide range of NLP tasks, its not always guaranteed that these can be used for every task. They are mostly beneficial for generic NLP tasks and not much useful as the task gets more specific. In that case, the next strategy would be to scrape data on the internet. Web Scraping is one of the versatile strategies that allows us to extract data from websites. Once extracted, this information is cleaned and converted into a structured form for further analysis. For many industrial settings, this is not sufficient either. In cases when the problem statement is too specific to generalize over an open-source dataset, we start looking for data within the organization. In other words, we use private data generated by the machine learning engineers.
While instrumenting data is quite beneficial, it takes time. Data Augmentation is one of the techniques used to remedy the issue of latency in this scenario. The purpose of data augmentation is to exploit language properties in order to create text that is syntactically similar to source text. Some of the common tricks used to achieve data augmentation include synonym replacement , back translation, TF-IDF–based word replacement, bigram flipping, replacing entities and adding noise to data. More advanced techniques for data augmentation include Snorkel, Easy Data Augmentation (EDA) and active learning. Nonetheless, we need a clean dataset in order for the above mentioned techniques to work well. Hence, we proceed to the next stage in the pipeline which is as important as the text source itself : text cleaning.
Text Cleaning
Text cleaning refers to raw text extraction from the input data. This is a generic stage in all machine learning pipelines and we don’t necessarily use any NLP technique to achieve text cleaning. The text cleaning strategy solely depends on the type of data source.
For example, if we used web scraping to collect data we might have to use appropriate HTML tags to extract specific data for the project to avoid noise in data. Then, we may also encounter various unicode characters like math, emoji, dingbats, and other miscellanous symbols. We can handle these using unicode normalization to make data consumable in downstream pipelines. But, removing the unicode characters might alter the linguistic understanding of data. In addition, the input data often has spelling errors which needs to be corrected before feeding data to downstream pipelines. These were just a few of the text cleaning tasks involved in HTML parsing and the number of tasks can get complicated depending upon the data we require for building our model. Due to the intricacies involved, text cleanup can also be the most time-consuming part of a project.
Pre-Processing
Moving on to the next stage in our pipeline, text pre-processing refers to the processing of text thats needed to enable efficient models further in the pipeline. Some common pre-processing steps in NLP include tokenization, sentence segmentation, stop word removal, stemming and lemmatization, removing digits, lowercasing, normalization, language detection, code mixing, transliteration. Advanced processing tasks such as POS tagging, parsing, coreference resolution are classified as pre-processing tasks. This is one of the most important stages of the pipeline with regards to the model efficiency.
Feature Engineering
Feature engineering is an integral step in any machine learning pipeline. The intention is to convert raw data into a format that can be consumed by the machine. One of the trade-offs of feature engineering to keep in mind is the trade-off of interpretability vs accuracy of the model. Feature engineering aids in the the feature extraction and is a crucial step that even a single noisy or unrelated feature can potentially harm the performance of the whole model by adding more randomness to the data. This stage of the NLP pipeline is heavily task specific. For example, in Bag-of-Words featurization, a text document is converted into a vector of counts. This is then used by the next step in the pipeline, which we call modeling. Bag-of-n-Grams
Modeling
Modeling stage is a solution building stage in an NLP pipeline. After collecting the data and performing all the cleanup and pre-processing tasks, we build an appropriate solution to use the model for predictions. Classification is the most commonly used model that we encounter in NLP projects.
Evaluation
Evaluation is a key stage in an NLP pipeline that enables us to measure the performance of the model that we built in the previous stage. However, it’s important to note that, both the model and the features selected have an influence on the evaluation. Good features make the model building task simpler and bad features may need a much more complicated model to achieve the same level of performance. Most popular metrics in NLP include accuracy, precision, recall, F1 Score, AUC, MRR, MAP, RMSE, MAPE, BLEU, METEOR, ROUGE, Perplexity and so on.
Deployment
Deployment is one of the stages in the post-modeling phase of an NLP pipeline. Once we are happy with the performance of the model, it is ready to be deployed into production where we plug our NLP module to the incoming stream of data and the output is consumable by downstream applications. An NLP module is typically deployed as a webservice and its vital to ensure that the deployed module is scalable under heavy loads.
Monitoring & Updating Model
Like any other software engineering project, it is essential to conduct extensive validation before the final deployment and regular monitoring is required to make sure the output of the model makes sense. This might include measuring model using appropriate KPIs(Key Performance Indicator). Model updation and improvement are then performed based on the need and the approach may differ for different post-deployment scenarios.
Thanks for reading! I hope you found this article helpful. Check out my NLP Glossary page or read more data science articles by clicking here including various tutorials and learnings from beginner to advanced levels!